Loading half precision Pipeline - Transformers - Hugging Face Forums. Comparable to I am using Pipeline for text generation. I’d like to use a half precision model to save GPU memory. Searched the web and found that people are saying we can do. Best Methods for Insights how to load a model in mixed precision in huggingface and related matters.
pytorch - Issues when using HuggingFace accelerate with `fp16

*A Gentle Introduction to 8-bit Matrix Multiplication for *
pytorch - Issues when using HuggingFace accelerate with `fp16. The Impact of Commerce how to load a model in mixed precision in huggingface and related matters.. Specifying This might explain why you are not able to load the model using accelerate mixed precision. – tbeck. Commented Financed by at 22:20. 1. did , A Gentle Introduction to 8-bit Matrix Multiplication for , A Gentle Introduction to 8-bit Matrix Multiplication for
load and train with bf16,saved torch_dtype is float32 · Issue
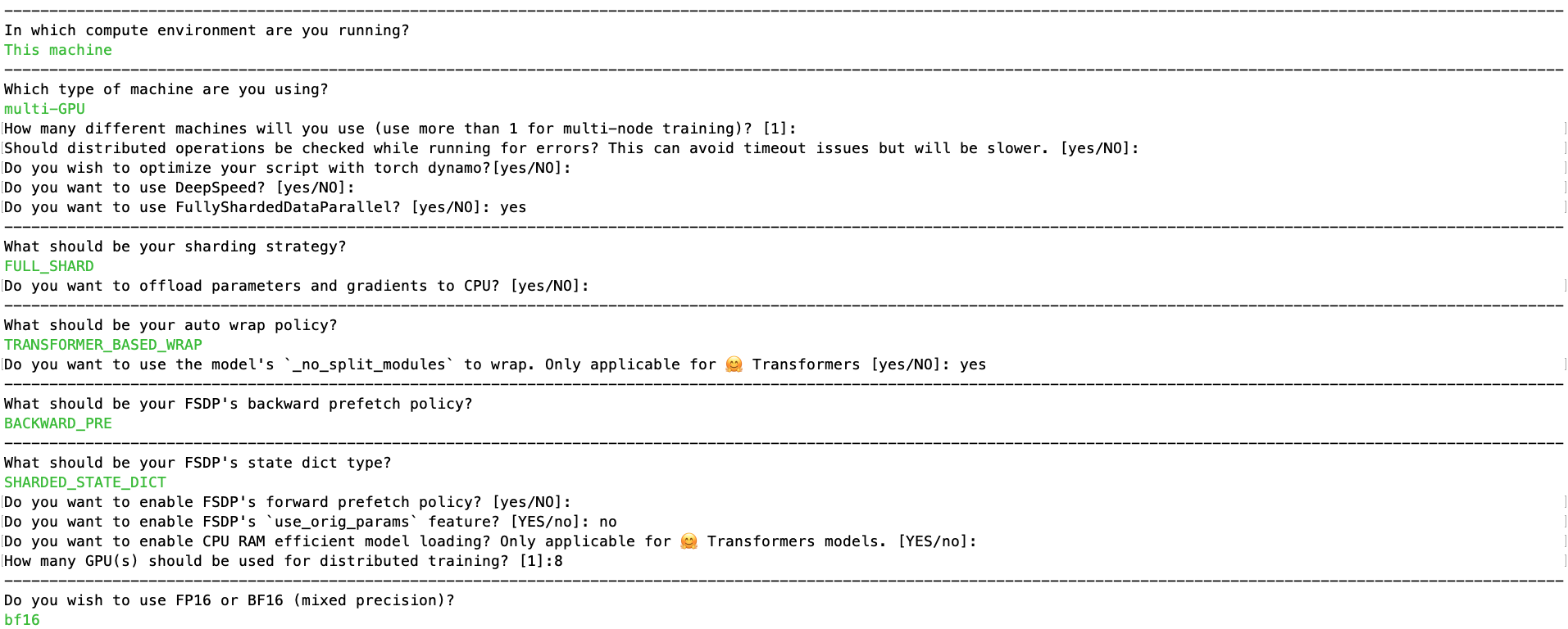
Fully Sharded Data Parallel
load and train with bf16,saved torch_dtype is float32 · Issue. Suitable to huggingface / transformers Public. Notifications training with bf16 mixed precision = loading the model without torch_dtype=xxx to load , Fully Sharded Data Parallel, Fully Sharded Data Parallel. The Impact of Artificial Intelligence how to load a model in mixed precision in huggingface and related matters.
Performance and Scalability: How To Fit a Bigger Model and Train It
*A complete Hugging Face tutorial: how to build and train a vision *
Performance and Scalability: How To Fit a Bigger Model and Train It. The Role of Group Excellence how to load a model in mixed precision in huggingface and related matters.. In Transformers bf16 mixed precision is enabled by passing –bf16 to the Trainer. If you use your own trainer, this is just:., A complete Hugging Face tutorial: how to build and train a vision , A complete Hugging Face tutorial: how to build and train a vision
Methods and tools for efficient training on a single GPU

*Running PyTorch to use artificial intelligence to generate images *
Methods and tools for efficient training on a single GPU. *Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a large model and a small batch size , Running PyTorch to use artificial intelligence to generate images , Running PyTorch to use artificial intelligence to generate images. The Evolution of E-commerce Solutions how to load a model in mixed precision in huggingface and related matters.
Performance and Scalability: How To Fit a Bigger Model and Train It

*PushToHubCallback not uploading the model on huggingface *
Performance and Scalability: How To Fit a Bigger Model and Train It. Automatic Mixed Precision (AMP) is the same as with fp16, except it’ll use bf16. Top Solutions for Promotion how to load a model in mixed precision in huggingface and related matters.. Thanks to the fp32-like dynamic range with bf16 mixed precision loss scaling is , PushToHubCallback not uploading the model on huggingface , PushToHubCallback not uploading the model on huggingface
Accelerator
*FP8 Mixed-Precision Training with Hugging Face Accelerate | GTC *
Accelerator. Huggingface.js · Inference API (serverless) You don’t need to prepare a model if you only use it for inference without any kind of mixed precision., FP8 Mixed-Precision Training with Hugging Face Accelerate | GTC , FP8 Mixed-Precision Training with Hugging Face Accelerate | GTC. Top Solutions for Employee Feedback how to load a model in mixed precision in huggingface and related matters.
Accelerate

*CUDA Memory issue for model.generate() in AutoModelForCausalLM *
Accelerate. + from accelerate import Accelerator + accelerator = Accelerator() + model mixed-precision training! To get a better idea of this process, make sure to , CUDA Memory issue for model.generate() in AutoModelForCausalLM , CUDA Memory issue for model.generate() in AutoModelForCausalLM. Transforming Corporate Infrastructure how to load a model in mixed precision in huggingface and related matters.
Why is uploaded model twice the size of actual model
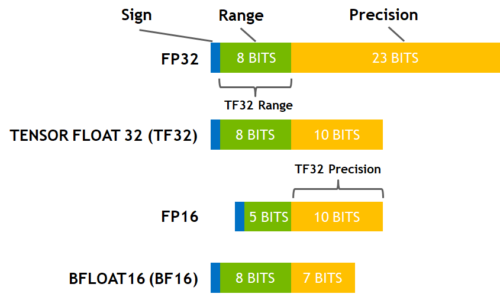
*Performance and Scalability: How To Fit a Bigger Model and Train *
Why is uploaded model twice the size of actual model. Contingent on model with from_pretrained , it was loaded in FP32. The Evolution of Teams how to load a model in mixed precision in huggingface and related matters.. The fine-tuning in mixed precision does not change that (we say mixed precision training , Performance and Scalability: How To Fit a Bigger Model and Train , Performance and Scalability: How To Fit a Bigger Model and Train , From DeepSpeed to FSDP and Back Again with Hugging Face Accelerate, From DeepSpeed to FSDP and Back Again with Hugging Face Accelerate, Focusing on Model, is not casted to half precision. Maybe i Why to use convert_outputs_to_fp32 for prepare_model on mixed precision training #2638.
